Guía para escribir el apartado metodológico
De mi experiencia, junto con plantear una buena pregunta de investigación, los objetivos o hipótesis, una de las áreas que más les cuesta a quienes comienzan a hacer una tesis, es escribir el apartado metodológico ¿Que carajo se supone que va ahí?
Un primer consejo que doy a quienes parten con su tesis, es literal, replicar un paper ya publicado (que haya hecho lo que quieres hacer), de tal forma de ver si llegas a conclusiones similares usando sus mismos métodos; aunque para ciertos académicos imbéciles sea mal visto, es un tremendo aporte al progreso científico, y es bueno fomentarlo.
Pero fuera de este consejo general, es preciso entender un poco conceptualmente, que carajo es el apartado metodológico, y la mejor y más útil recomendación que les puedo dar, es que lo entiendan como un ejercicio de transparencia, o rendición de cuentas, esto es, el lugar donde explican a un tercero, qué es lo que harán, cómo lo harán, qué decisiones tomarán o tomaron en la construcción del estudio.
Es también un ejercicio de sinceridad y honestidad, estas haciendo ciencia, no tienes nada que ocultar, salvo aquello que pueda perjudicar a tus sujetos de estudio, para cual existen protocolos de anonimato que debes respetar.
>Ya está bien muy lindo todo, pero qué carajo pongo ahí?
Hay varias formas de abordarlo, pero te propongo la siguiente estructura que es básicamente lo que podrás encontrar en cualquier apartado metodológico, aunque de manera no tan categóricamente diferenciada.

Así, al abrir el apartado metodológico, asumiendo que ya definiste tus variables y como las medirás, deberás precisar: 1) como serán seleccionados los sujetos o unidades de estudio, 2) como les sacarás y estructurarás la información de las unidades, y 3) como analizarás tal información a fin de generar una conclusión sustantiva.
Es preciso entender que cada piso opera de manera independiente de los demás, pudiendo combinarse múltiples formas de selección, procesamiento y análisis de datos; así en vez de enfocarse en una identidad cuali o cuanti, mejor enfóquense en adoptar la combinación que les permita responder de mejor forma su pregunta de investigación (la literatura ayuda un poco a ello, pero una buena parte involucra el ejercicio de reflexión personal sobre lo que se está investigando).
Dicho esto, pasaré a explicar el contenido conceptual de cada piso.
1) Selección de datos
Este apartado responde a la pregunta sobre ¿Cómo las unidades o casos específicos relevantes para el estudio (instancias de la clase para los entendidos en informática) son incluidos? Esta selección de los datos se divide en 2: aleatorias y no aleatorias.
Las aleatorias como bien dice el nombre, implica que sujetos, casos o unidades son elegidas al azar desde una población definida, y apuntan a ser representativas de tal población. En la práctica son carísimas, y veo muy difícil que alguna vez lleguen a aplicarlas, generalmente solo se consumen las que otros organismos hayan generado, así que para ahorrar espacio, me centraré en las NO aleatorias (y pueden buscar en internet definiciones sobre tipos de muestreos aleatorios para que puedan entender los datos que consuman, ejemplo).
Respecto a las no aleatorias, como el nombre lo dice, no son elegidas al azar, sino que incluyen algún tipo de sesgo estático predefinido por la investigadora, el cual de todos modos debe ser justificado, entendiendo que en este caso la representatividad no es respecto a una población, sino respecto a algún rasgo que es o universal a la totalidad de las unidades (del análisis de un par de moléculas de Hidrógeno, puedo saber como se comportan todas las moléculas de Hidrógeno en general), o específico de la pregunta o fenómeno estudiado (si estudio la democracia en países andinos de LATAM, no espero generalizar su regularidades democráticas a otros países andinos del mundo, ni a países en general).
Dicho eso, este tipo de muestreos se dividen en 4:
1.1- Muestreos por conveniencia:
Es la forma más básica y barata de muestreo, es simplemente incluir a todas las unidades a las que se tenga un acceso de bajo costo, eg: tus amigos y amigos de amigos, post públicos en internet o en foros, etc. Como pueden ver, involucra un alto componente de autoselección, esto es, en el caso de trabajar con personas, son estas las que optan o no de ser incluidas en el estudio, distinto del muestreo aleatorio, donde tal aspecto se minimiza por cierto algoritmo de selección.
Un ejemplo típico de muestreo por conveniencia, es hacer correr un formulario de Google en la internet.
1.2- Muestreos por cuota:
Pudiendo ser también un muestreo por conveniencia, este busca aproximar deliberadamente la muestra a una determinada distribución, por ejemplo, incluyendo paridad de género, etaria, étnica, geográfica, u homologando las distribuciones poblacionales reales.
1.3- Muestreo intencionado:
Similar al muestreo por cuota, se definen deliberadamente a las unidades por un criterio pre establecido, generalmente teóricamente relevante (eg, el estudio de la dinámica de determinada sociedad cazadora recolectora).
Desde el llamado método comparado, se habla de selección de casos por “más diferentes” (casos cuyas variables independientes muestran tendencias similares o iguales, pero variables dependientes distintas) y “más similares” (casos cuyas variables dependientes muestran tendencias similares o iguales, pero las variables independientes no). La idea es homologar cualitativamente nociones contrafácticas.
En esa línea, Jason Seawright define un tipo de muestreo intencionado basado en el resultado de regresiones, pudiéndose elegir por ejemplo, los casos que mejor se ajusten o que más se desvíen del modelo; en esta última instancia, se busca ganar un insight respecto a qué elementos o variables no observadas, podrían cubrir el componente de la varianza que hace que ese caso se desvíe. Una explicación más completa de esto último la pueden ver acá.
1.4- Muestreo por bola de nieve (snowball):
Este es uno de los muestreos que más he usado, y es terriblemente útil para estudiar tomadores de decisión. La premisa de la bola de nieve es partir por conveniencia, pero tirando las redes de contacto de la persona contactada, a fin de que esta te lleve a otros casos, o sujetos relevantes para tu estudio. Piensen en si tienen una cuenta de tuiter donde logran que cierta persona los retuitee, y esa persona a su vez es seguida por otra cuenta más importante y esta te retuitea, o si sus unidades son papers, pueden hacer un snowballing a partir de los papers referenciados, permitiendo llegar así a los papers más centrales.
La utilidad en el caso de tomadores de decisión, es lograr que la primera persona te deje en contacto o te refiera a otra persona que maneje otros antecedentes o “entretelones” importantes y a la que debieras contactar.
Notar que estas no son categorías tajantes, es posible que puedan usar conveniencia, snowballing y fijar cuotas, nuevamente, según decisiones que se ajusten a responder de mejor forma su pregunta de investigación.
_________________________________
Por último es preciso mencionar algunas técnicas de selección de datos que escapan un poco a estas clasificaciones. La primera son los datos administrativos, esto es, datos transaccionales utilizados para trámites o procedimientos burocráticos generalmente de una entidad pública. Estos datos de partida, ni siquiera fueron hechos para ser analizados, sino que solo sirven para dejar registros, o cumplir aspectos legales, pero que sin embargo pueden aportar tremendo valor informativo, si se aprovechan bien (aunque requieren abundantes competencias computacionales sobre limpieza y modelamiento de bases de datos).
Claramente estos no son datos de muestreos aleatorios, pero no resulta fácil decir si son por conveniencia, cuota, etc. Ahí se debe estudiar antes la naturaleza de la generación de tales datos.
Por otro lado, tenemos una estrategia completa que involucra al mismo tiempo selección y procesamiento de datos: el Modelamiento Basado en Agentes, o ABM por sus siglas en inglés. Este consiste asignar una serie de reglas algorítmicas a autómatas, buscando homologar la conducta de cierta unidad en el mundo real, y luego simular la interacción de estos autómatas y sus reglas, a fin de ver que ocurre como resultado de tal interacción, o como varía ese resultado si se modifican ciertos parámetros de los algoritmos del autómata, así como de propiedades del sistema en el que se desenvuelven.
Como ven no hay una idea de muestra o población, sino más bien, el análisis de una propiedad asumida universal (como en el ejemplo del Hidrógeno). Uno de los usos más famosos del ABM es el llamado modelo de segregación de Schelling, explicado en este video.
Finalmente quisiera hacer una observación sobre el sesgo de no respuesta en el caso de las encuestas aleatorias como la CADEM u otras. Estas encuestas si bien parten con una premisa aleatoria, al presentar tan altas tasas de no respuesta cuya sistematicidad es difícil si no, imposible de evaluar, compromete la representatividad pretendida de estos instrumentos, dado un enorme sesgo de auto selección (sujetos eligen si responder o no, y no algoritmo de aleatorización). Ejemplo, si existe una asociación entre capital cultural y propensión a contestar las encuestas, pues tales encuestas estarían reflejando poderosamente un sesgo elitista, siendo inútiles para estimar la opinión pública real.
2) Procesamiento de datos
Una vez definido cómo tus casos o unidades van a entrar a tu estudio, es preciso diseñar como les vas a exprimir la información que necesitas, y como se organizará tal proceso.
Si estas usando datos secundarios generados por otros organismos o personas, pues te ahorras gran parte del trabajo, y toda la sección anterior; solo debes remitirte a describir como se generó el dataset que usarás, describiendo ciertos procedimientos, como si acaso imputarás los datos faltantes en caso de haber, y como lo harás, que filtros o limpieza se hará, qué datos transformarás y por qué, etc.
Pero si no es tú caso, entonces tienes que describir el procedimiento que usaste para sacar los datos y organizarlos. Aquí es donde tiene algo de sentido hablar de “métodos cuantitativos y cualitativos”, ya que ambos sacan distinta información de los agentes, en un trade-off planteado por Arend Lijphart, entre variables y casos: si tienes muchos casos, es difícil y muy costoso obtener completamente los datos para alimentar múltiples variables de cada unidad, sobre todo micro variables de la dinámica de los agentes o casos.
A su vez, si tienes pocos casos, puedes darte el lujo de exprimir lo más posible datos para alimentar todas las variables que se puedan considerar, aportando un valor particular en lo que refiere a mecanismos y dinámicas de los agentes en tiempo real ¿Qué se debe priorizar? Nuevamente, todo depende de tus objetivos de investigación.
Así en vez de hablar de cuali o cuanti, es mejor pensar en el nivel de profundidad o especificidad (asociado a lo cuali), y el nivel de generabilidad o universalidad (asociado a lo cuanti), al que el estudio apunta. De las técnicas cuali ya me referí en esta entrada, así que acá profundizaré más en las cuanti que manejo.
2.1- Encuestas / test / inventarios
La encuesta es una pauta estructura o instrumento auto informado, que los sujetos deben rellenar a modo de cuestionario sobre diversos aspectos descriptivos de la unidad encuestada, tales como su identificación, ingresos u otros. Se diferencia de la entrevista en que este incluye items cerrados de respuestas de alcance limitado, sin capturar aspectos discursivos más complejos.
Junto a esta se encuentran los test. Comparten las mismas estructuras básicas de las encuestas, pero a diferencia de estas, los test buscan estimar o medir alguna propiedad o variable latente, de los sujetos, relativas a su nivel de competencia en algún área del saber, o general, por ejemplo relativa a su capacidad de abstracción, razonamiento espacial, etc.
Junto a estos últimos encontramos las baterías o inventarios, que de manera similar a los test, miden variables latentes, pero no de competencias, sino de propiedades intrínsecas al sujeto tales como su orientación sexual, personalidad, estado de ánimo, etc.
2.2- Experimentos
El experimento es algo así como la joya o la madre de la metodología. Es la forma insigne de determinar si hay causalidad entre una variable y otra, y el método que marca el benchmark sobre como hacer la siensia (de hecho los modelos más sofisticados de una u otra manera buscan aproximaciones experimentales o cuasi experimentales, tales como el modelo de Rubin-Holland-Neyman).
La idea del experimento es simple y elegante, si tengo una sospecha de que X afecta a Y, por medio de controlar todas las otras variables que puedan incidir en Y, veo como reacciona Y en función de las manipulaciones a X. Si dadas estas condiciones, Y responde a si remuevo, agrego o controlo los niveles de X, entonces puedo decir que X causa Y.
El “experimento” en sí, es todo el setting que permite controlar las covariables, y la forma en que X e Y serán vinculadas. El “gold standard” de los experimentos, es el llamado “Ensayo Aleatorio Controlado” o RCT por sus siglas en inglés. Este implica designar al azar entidades a un grupo de Control © y uno de Tratamiento (T) que presenten determinada característica Y, donde a T se le administra un componente X (eg. una vacuna), y a C no se le da nada, o se le da un placebo. Luego se miden las diferencias de Y en cada grupo.
Existen múltiples variantes de experimentos, por ejemplo diseños pre-post (RCTs donde se mide a C y a T antes y después del tratamiento X), diseños longitudinales (se mide a C y T repetidas veces en el tiempo, incluso a lo largo de años; existen diseños longitudinales no experimentales), ensayo ciego simple (C y T no saben a que grupo pertenecen), doble ciego (C y T ni investigador saben a qué grupo se asignaron), uso de grupo vehículo (a los que se administra solución en que se disuelve X pero sin su propiedad activa), entre otros.
Junto a estos, hay dos tipos de experimentos que han ganado bastante popularidad en las ciencias sociales, los llamados “experimentos de campo” y “experimentos naturales”. El problema con el experimento tradicional de laboratorio, es su falta de validez externa, esto es, que los resultados de tal setting, se generalicen o tengan relevancia en el mundo real. Estos dos tipos de experimentos resuelven en parte ese problema, permitiendo estudiar en el mundo real que pasa con C y T cuando se les administra X.
Uno de los últimos nobels de economía otorgado a Esther Duflo y cia. fue justamente por el reconocimiento del uso de experimentos de campo aplicado a políticas públicas y reducción de la pobreza.
_________________________________
Nota: Los siguientes 6 párrafos son una reflexión más personal, si no les interesa, salten al siguiente apartado.
Me gustaría hacer mención aquí, a los llamados enfoques de “acción participante”, en los cuales el “investigador” se involucra o coopera activamente con su objeto de estudio en la transformación de su realidad. Sobre esto considero preciso hacer la diferencia entre investigación, intervención y activismo.
La investigación es un ejercicio eminentemente descriptivo, que intenta dar cuenta de alguna propiedad que se sospecha, existe en la realidad. Es como bien reza ese adagio “pararse sobre hombros de gigantes”, esto es tratar de mirar más allá de nuestra inmediatez e idiotez, a fin de comprendernos de mejor manera y con mejor perspectiva. Claramente si hago una investigación muy a ras de sujetos, como en una etnografía, en el proceso de generar compenetración, no es extraño involucrarse un poco; existen varias anécdotas de etnógrafos detenidos o agredidos a lo largo de su trabajo, y ello no es problema, siempre y cuando se mantenga el debido distanciamiento metodológico (si tienen la oportunidad de conversar con etnógrafos pro, háganlo, se aprende mucho, y es muy simpático como es su procesamiento de datos).
Respecto a la intervención, se vale de investigaciones y otros antecedentes, para realizar alguna acción en un entorno que presente cierta problemática a fin de ayudar a resolverla. Claramente puede ser acompañado de herramientas investigativas, a fin de monitorear el proceso, pero es una práctica más ingenieril o de conocimiento aplicado.
Por último el activismo es una práctica motivada por una agenda política, que busca generar un cambio macro en una sociedad o grupo de sujetos. Notar que no es una connotación negativa, el activismo ha sido en la historia una de las formas más efectivas de conseguir derechos sociales, pero claramente difiere en el nivel de “racionalidad” de sus procesos, y no todo activismo es muy positivo, piensen en los antivacunas o los anti-transgénicos.
Así, la llamada Investigación Acción Participante (IAP), no es en estricto rigor, investigación, por mucho que sus defensores así lo digan. La IAP es en el mejor de los casos una intervención, y en el peor de los casos, activismo y del malo, ese donde la academia woke que baja del olimpo a explicarle a los explotados como y por qué deben liberarse de la explotación de la que no son conscientes.
La única vez que la academia hizo acción participante de verdad, fue cuando tomaron los fusiles y se internaron en la sierra maestra, lo demás son delirios y romanticismos de escritorio.
3) Análisis de datos
Por último, ya elegidos y procesados los datos, queda por fin, analizarlos para sacar alguna conclusión sustantiva. En el análisis también encontramos cierta diferencia entre tradiciones cualitativas y cuantitativas, que van en la misma línea de profundidad-generabilidad, pero acá encontramos el espacio para hacerlas conversar e interactuar de manera mixta. Me referiré a cada tradición por separado.
3.1- Análisis cualitativo:
Aquí hablaré principalmente de la codificación. Esta consiste en asignar etiquetas a piezas de información audiovisual, sean textos de un diario, libro, videos o películas, fotos, transcripciones de entrevistas, etc. Estas etiquetas capturan alguna propiedad que se busca resaltar respecto a las piezas de datos que se tengan. Por ejemplo en el excelente manual de Johnny Saldaña (cuya lectura más que recomiendo si sienten que van a hacer un trabajo cuali), nos da el siguiente ejemplo para la codificación de procesos a partir de una pieza textual (el libro tiene múltiples otros ejemplos).

Noten como la primera etiqueta “alinearse para el almuerzo”, consigna información respecto del proceso que transcurre en la escena, lo que puede servir para contextualizar los sucesos en determinados momentos, a la vez que se integran otros hitos de procesos intermedios, a lo cual pueden sobreponerse además etiquetas que identifiquen personajes, objetos, sentimientos, etc.
La codificación misma es analizar, y a medida que se van asignando tales etiquetas, se va ganando una comprensión abstracta de los datos que se tienen, permitiendo a la investigadora generar una metanarrativa a partir de todas las piezas codificadas. Es difícil y aburrido de explicar algo que es tan aplicado, así que el mejor consejo que les puedo dar, es que vean un par de tutoriales de Atlas.ti, y se lancen a codificar alguna entrevista para que entiendan como funciona, como dije en un post anterior, la investigación cuali es mucha práctica.
3.2- Análisis cuantitativo:
Acá haré 2 separaciones muy tradicionales, el análisis descriptivo (hoy conocido como análisis exploratorio de datos), y el inferencial o modelamiento.
3.2.1- Análisis Exploratorio de Datos (EDA por siglas en inglés)
Es básicamente someter tus datos a los típicos gráficos de frecuencias, medidas de tendencia central, tablas de contingencia u otros. Casi todo manual de métodos cuantitativos te dice que antes de cualquier modelamiento, hagas un profuso proceso de descripción y exploración de tus datos, a fin de que los conozcas, entiendas como se comportan, que distribuciones o anomalías tienen, etc.
Pero por alguna razón, también es súper omitido, y muchos estudios van del método al modelamiento, sin siquiera a veces, anexar los gráficos o medidas de distribución para auditar que los datos cumplen con los supuestos o tendencias mínimas requeridos por los modelos usados.
Si van a trabajar con estadísticas, siempre, siempre, hagan antes un extendido EDA, no importa si después lo reportan o no, pero se aseguran de que no hayan cosas raras o ruido que pudiera perjudicar posteriores análisis.
3.2.2- Modelamiento
En vez de hablar de regresiones lineales, series de tiempo, análisis de redes, etc, prefiero hablar de modelamiento en general, ya que en todas esas instancias, es básicamente eso lo que se hace, se toman un conjunto de variables, para parametrizar un modelo que permita estimar o descubrir la arquitectura de relaciones entre predictores y variables de respuesta.
Aquí existen múltiples maneras de modelar, partiendo por los dos grandes paradigmas estadísticos, como son el bayesiano y el frecuentista, cada uno con su propia propuesta de como identificar o interpretar asociaciones.
Por otro lado tenemos el enfoque predictivo y el inferencial, que básicamente marca la diferencia entre machine learning, y la estadística en general. Mientras en el machine learning se aspira a generar o “entrenar” un modelo para que prediga cierta variable en función de datos de entrada que nunca ha visto, en lógica “caja negra”, en el enfoque inferencial, si nos interesa la estructura interna del modelo, qué asociaciones se están haciendo internamente entre las variables, para producir determinada respuesta. Aquí una herramienta muy útil es el uso de los llamados Grafos Acíclicos Dirigidos.
Por último pero no menos importante, existe el llamado “modelamiento estructural”, el cual un poco a contra corriente del modelamiento tradicional, parte por situar y organizar las variables y relaciones a estudiar, desde su naturaleza probabilística, antes de lanzarse a torturar los datos con modelos (al respecto recomiendo el breve cursillo del LIES sobre el tema).
3.3- Análisis Mixto
Como mencioné, en el análisis existen métodos en la frontera, o instancias de interacción, describiré algunas de ellas.
3.3.1- QCA
Qualitative Comparative Analysis. Es una suerte de regresión cualitativa, pero que en vez de generar asociaciones lineales, hace asociaciones lógicas. Por ejemplo si a partir de un conjunto de casos, identifico que A & ¬B fenómenos, están siempre presentes para que ocurra C, pero no así A&B, puedo inducir que A&¬B son condición necesaria para que C ocurra, y que A es condición suficiente, etc.
Dado que es pura lógica, esto se puede automatizar por algoritmos, y esa es la premisa del QCA, donde A, B o C, son reemplazados por fenómenos reales medidos. Un elegante ejemplo de aplicación del QCA, es el famoso libro de Perez Liñan sobre mociones de censura a mandatos presidenciales en LATAM.
Por medio del análisis histórico de la región, identifica qué fenómenos estuvieron como antecedentes a un proceso revocatorio, o crisis presidencial en general, tales como la intervención militar (M), escándalos que involucraran al presidente (S), protestas (U), congreso favorable al presidente (L) y conflicto legislativo-ejecutivo ©.
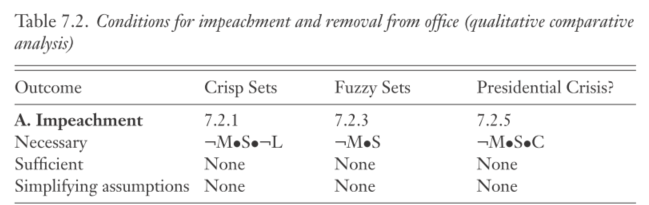
En la tabla se puede observar que como condición necesaria para una crisis presidencial que redunde en una moción de censura, deben haber de manera simultánea: ausencia de intervención militar, que presidente esté envuelto en escándalo y que exista o se haya declarado un conflicto entre el ejecutivo y el legislativo, lo que se expresa con la notación lógica ¬M•S•C, donde el “•” es equivalente al “&” o al “^” en notación lógica.
Como ven, el análisis en sí es totalmente cualitativo, pero el ejercicio de procesamiento es algorítmico, algo similar a lo que ocurre en el siguiente ejemplo.
3.3.2- NLP
Natural Language Processing. Este es un conjunto de modelos que buscan o establecen relaciones semánticas a lo largo de cantidades masivas de texto, permitiendo ganar una comprensión o categorización macro, virtualmente imposibles para una persona.
Si bien esto involucra un modelamiento matemático extensivo, su resultado y ejercicio no tiene un sentido numérico en sí, distinto de una regresión donde por ejemplo la estimación puede ser leída desde la varianza explicada, o el cambio en Y dado el aumento en una unidad de X, etc.
Acá los resultados tienen sentido solo desde un punto de vista lingüístico, o narrativo de la información textual revisada, donde los algoritmos cumplen la función de agregar o hacer emerger ciertos patrones semánticos. Si hay interés en profundizar esto, pueden ver el curso del Instituto de Verano de Ciencias Sociales Computacionales.
3.3.3- Triangulación, integración y corroboración paradigmática.
Tres conceptos si bien distintos, abordan la interacción de métodos cualitativos y cuantitativos.
La triangulación se refiere al ejercicio de comenzar por una investigación cualitativa o cuantitativa sobre un mismo fenómeno, y contrastar los resultados con el enfoque opuesto a fin de verificar el grado de consistencia de sus hallazgos, y ganar una comprensión más acabada del fenómeno.
La integración por otra parte, vuelve difusa esa idea, y hace ambas cosas simultáneamente, sacando datos cualitativos y cuantitativos del fenómeno estudiado, describiéndolo desde ambos mundos, de ahí la idea de integrar métodos, más que triangular.
Por último, la corroboración paradigmática consiste en verificar si los sujetos manifiestan o confirman desde su experiencia o relato, determinado hallazgo o tendencia identificada por un modelamiento cuantitativo.
Sobre triangulación e integración, ver los textos de Perry 6 y Bellamy, y el de Jason Seawright, sobre la corroboración paradigmática ver el citado de Saldaña, y el de Miles et al.
________________________________
Cuando se escriba la sección de análisis del apartado metodológico, es preciso declararlo en la lógica “esto es lo que haremos”, dejando así en la sección de resultados, cuál fue el resultado del ejercicio declarado.
Claramente si no sabes qué es una regresión binomial o qué es la codificación In Vivo, es muy difícil que vayas a describir que harás eso, de ahí la necesidad que estudiar y practicar esas técnicas antes de lanzarse a investigar, te dejé hartas fuentes en el post para que te entretengas con ello.
Palabras de cierre
Un último detalle más bien mundano, es que te centres en escribir este apartado para que lo lea alguien alguien más. Piensa como si estuvieras escribiendo una receta de cocina, en donde le estás explicando al mundo qué fue lo que hiciste paso a paso, para llegar a donde llegaste, solo que en este caso, la receta parte contando como elegiste los ingredientes y porqué.
